数据会聊天之用Python实现随机森林
发布时间:2021-10-23
##本期展示的数据分析例子和第一期逻辑回归相似,也是关于研究生录取,但有区别。今天的因变量Y={0,1,2},其中0表示不录取,1表示有待考虑,2表示直接录取。因此用简单的二元分类逻辑回归肯定不行,这里我们也不再使用多类别逻辑回归了,因为第一期里面我们说过逻辑回归的预测能力并不强。本期我们就展示应用非常广的一种集成学习方法随机森林,森林是由许多树组成的,如果没有树木只有草,那不叫森林,叫大草原。所以随机森林,就是随机地种许多树,什么树呢?决策树!因此随机森林除了可用于分类,当然也可以用于回归。
##加载程序包
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier # 随机森林程序包
from sklearn import metrics
import seaborn as sbn #数据可视化包
import tkinter as tk #制作GUI的程序包
import matplotlib.pyplot as plt
df=pd.read_csv("D:/mypy/admit.csv") # 数据我存在自己电脑D盘mypy文件夹里,读者可从附件下载
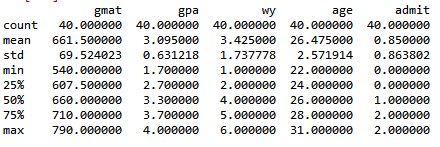
df.describe() #描述统计
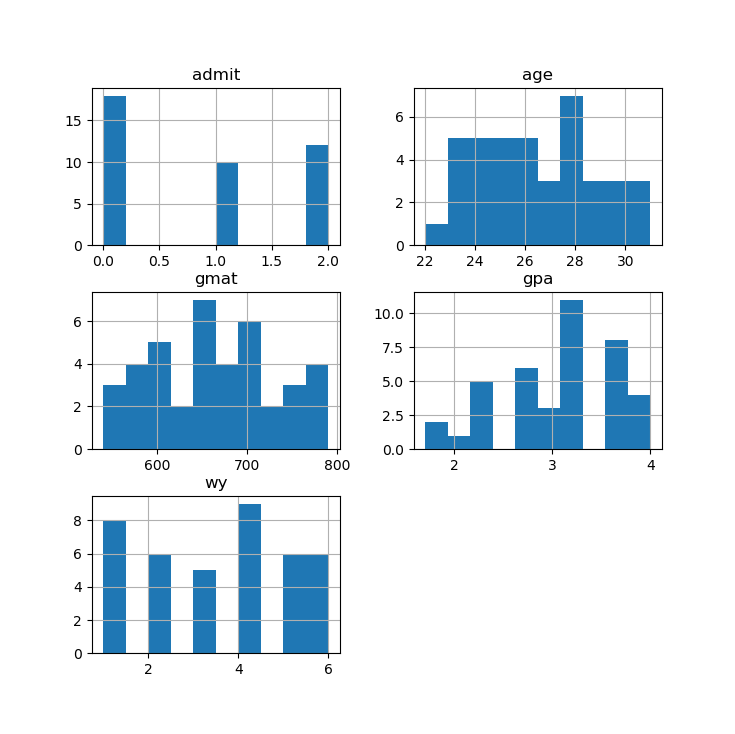
df.hist() # 变量直方图
X=df[['gmat','gpa','wy','age']] # 自变量
y=df['admit'] # 因变量
##训练和预测
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=23) #原始数据分为训练集测试集
clf = RandomForestClassifier(n_estimators=100)# 森林里100棵树
clf.fit(X_train,y_train) #训练集上拟合
y_pred=clf.predict(X_test) # 测试集上预测
##准确率展示
pd.DataFrame({'Y_test':y_test, 'Y_pred':y_pred}) #预测值与真实值对比

confusion_mat=pd.crosstab(y_test, y_pred, rownames=['Actual'],colnames=['Prediction']) #预测值与真实值列联表
confusion_mat

plt.figure()
sbn.heatmap(confusion_mat, annot=True) #热力图
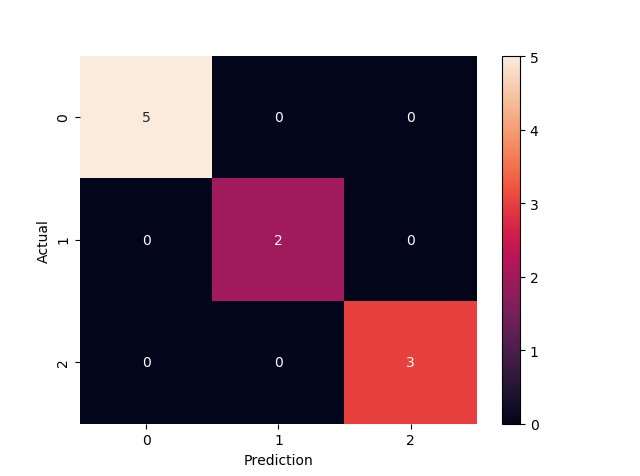
print('Accuracy:', metrics.accuracy_score(y_test, y_pred))# 准确度计算,100%,运气好!
#读者可尝试修改一下test_size或者random_state,或者修改树的数目,可能会得到不同结果
##新值预测
prediction=clf.predict([[730, 3.7, 4, 27]]) # 一位申请者,GMAT=730分,GPA=3.7, 工作4年,27岁
print('Predicted:',prediction) #预测结果是“2”录取
##制作一个简单GUI
root=tk.Tk()
canvas1 = tk.Canvas(root, width = 500, height = 350)
canvas1.pack()
# GMAT
label1 = tk.Label(root, text=' GMAT:')
canvas1.create_window(100, 100, window=label1)
entry1 = tk.Entry (root)
canvas1.create_window(270, 100, window=entry1)
# GPA
label2 = tk.Label(root, text=' GPA: ')
canvas1.create_window(120, 120, window=label2)
entry2 = tk.Entry (root)
canvas1.create_window(270, 120, window=entry2)
# work_experience
label3 = tk.Label(root, text=' Work Years: ')
canvas1.create_window(140, 140, window=label3)
entry3 = tk.Entry (root)
canvas1.create_window(270, 140, window=entry3)
# Age input
label4 = tk.Label(root, text='Age: ')
canvas1.create_window(160, 160, window=label4)
entry4 = tk.Entry (root)
canvas1.create_window(270, 160, window=entry4)
def values():
global gmat
gmat = float(entry1.get())
global gpa
gpa = float(entry2.get())
global work_experience
wy= float(entry3.get())
global age
age = float(entry4.get())
Prediction_result = (' Predicted Result: ', clf.predict([[gmat,gpa,wy,age]]))
label_Prediction = tk.Label(root, text= Prediction_result, bg='sky blue')
canvas1.create_window(270, 280, window=label_Prediction)
button1 = tk.Button (root, text=' Predict ',command=values, bg='green', fg='white', font=11)
canvas1.create_window(270, 220, window=button1)
root.mainloop() #到此制作GUI的程序完毕,见效果图如下
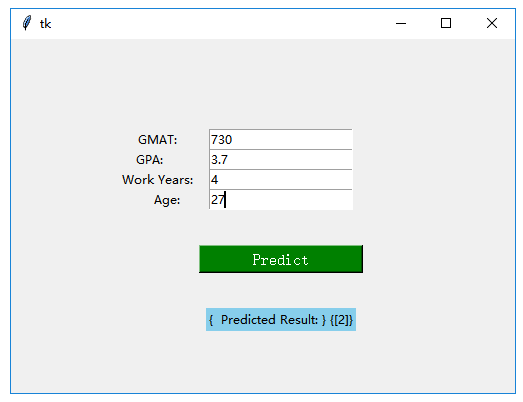
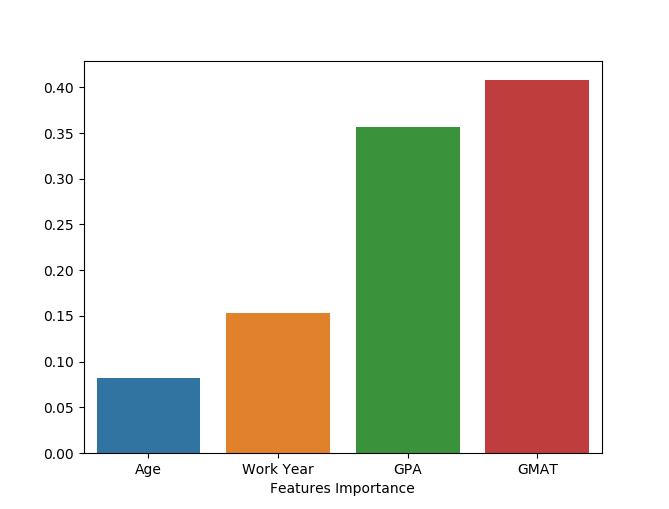
# 这样一位27岁,有4年工作经验,GMAT考730分, GPA为3.7的申请者,我们的模型很看好他,那么到底他的哪个特征对其录取贡献最大呢?这就是下面要解决的问题了。由以下结果,我们可知,年龄最不被看重,而GMAT成绩是最被看重的。
##变量重要度
featureImportances = pd.Series(clf.feature_importances_).sort_values(ascending=False)#随机森林可以对自变量的重要度进行计算
print(featureImportances)
fig=sbn.barplot(x=round(featureImportances,4), y=featureImportances) #用条形图对比一下重要度,原来是GMAT最重要
fig.set(xticklabels=['Age','Work Year','GPA','GMAT'])
plt.xlabel('Features Importance')
plt.show()